C++八股
面试可能会涉及到的C++知识点
编译过程
预处理:处理
#开头的预处理指令,展开宏定义、包含头文件(即把头文件代码添加到对应文件中)、处理条件编译指令1
g++ -E main.cpp -o main.i # 查看预处理后的代码
编译:将代码翻译成汇编代码(模板实例化发生的阶段)
1 2
g++ -S main.cpp -o main.s # 查看汇编代码 g++ -fdump-ipa-template main.cpp # 查看模板实例过程
汇编:将汇编代码翻译成机器码(该阶段有时与编译阶段合并)
1
g++ -c main.cpp -o main.o # 查看生成的目标文件
链接:将多个目标文件合并和库文件链接生成可执行文件或者库文件
静态链接库与动态链接库
静态链接库
- 文件扩展名:linux下
.a,windows下.lib - 编译时被链接到可执行文件中,占用内存空间大
- cmake构建静态库,使用
add_library(libname STATIC SRC) - cmake链接静态库构建可执行文件,使用
target_link_directories(),等同于编译指令中的-L参数,然后target_link_libraries(),等同于编译指令中的-l参数
动态链接库
- 文件扩展名:linux下
.so,windows下.dll - 运行时才被载入,可以实现进程间共享,因此其也被称为共享库
- cmake构建动态链接库,
add_library(libname SHARED SRC) - cmake链接动态链接库,需要链接
liblibname.dll.a静态库,然后将.dll文件放在可执行文件的目录下即可在运行时链接动态链接库
语言基础
C++内存模型
堆:new分配的内存块,
栈:编译器在需要时分配,在不需要时自动清理的区域,存放局部变量和函数参数
全局/静态存储区:这两部分被放在同一块内存中,在C语言中未初始化的放在.bss段,初始化的放在.data段;C++中不做区分
常量存储区:存放常量
代码区:存放代码(如函数),不允许修改,但是可以执行
直接初始化和拷贝初始化
- 拷贝初始化:使用=初始化变量,把等号右边的初始值拷贝到新创建的对象中,如
string a = "123"; - 直接初始化:不用等号为直接初始化,如
string a("123");
const修饰符
修饰变量表示该变量只读,其不可以被改变
修饰成员函数,表示该成员函数无法修改成员变量
修饰指针时,其分为底层const(即指向常量的指针),和顶层const(即常量指针,指针自身是常量);注意,不能将底层const作为右值赋给非底层const对象,这样就可以通过该对象修改指向的常量,不符合初衷
1 2 3 4
int a = 1; int * const cp = &a; // 顶层const const int * p = &a; // 底层const int *q = p; // 不合法,将底层const作为右值赋给非底层const指针
修饰引用时,只要指向常量的引用,由于引用自身不是对象,因此不存在常量引用
虚函数与多态
定义虚函数的关键词为
virtual,如果=0则为纯虚函数,派生类必须实现基类定义的纯虚函数通过虚函数,由基类指针指向的派生类对象,可以访问其派生类实现的虚函数,而普通函数,则只能访问基类的函数
即使用类的指针调用函数时,普通函数由指针的类型决定;而虚函数由指向的对象的实际类型决定
对于类而言,一般情况下其存在堆区和代码区,函数存放在代码区由类的所有对象公有,而成员变量存放在堆区,由对象独立拥有,因此在使用类的指针调用普通函数时,其会根据指针的类型,去到对应类型的代码区找到函数的实现,所以调用普通函数时,由类指针的类型决定
对于拥有虚函数的类,在其堆区会存在一个虚函数表指针,每个对象都有其自己的虚指针,在调用虚函数时,会通过对象的虚函数表指针,找到其虚函数表(存放在全局数据区),然后再通过虚函数表找到存放在代码区的具体函数实现
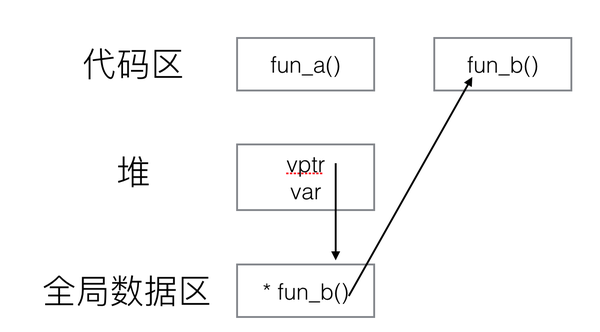
对于析构函数,一般将其声明为虚函数,即虚析构函数,因为希望在析构时,能够调用派生类的析构函数
拥有虚函数的类,其对象在起始位置处会有虚函数表(vptr)指向该类所对应的虚函数标(vtb),虚函数表中存储着指向虚函数的指针
通过值进行调用,而非指针并不会发生动态绑定,其在编译时就能够确定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
void f(); void g(); class Base { public: virtual void foo() { f(); } }; class Derived: public Base { public: virtual void foo() { g(); } }; void test(Base b) { b.foo(); }
final对虚函数的多态性具有向下阻断作用。经final修饰的虚函数或经final修饰的类的所有虚函数,自该级起,不再具有多态性。考虑如下情景,使用final修饰函数foo,则foo函数的多态性在此处被阻断,因此其调用就在编译时确定,而不是运行时动态绑定(即通过查虚函数表来调用)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
void f(); void g(); class Base { public: virtual void foo() { f(); } }; class Derived: public Base { public: virtual void foo() final { g(); } }; void test(Derived* d) { d->foo(); }
如果将该类声明位
final,则此类的多态性就此阻断,即其所有虚函数的调用都是确定的1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
void f(); void g(); class Base { public: virtual void foo() { f(); } }; class final Derived: public Base { public: virtual void foo() { g(); } }; void test(Derived* d) { d->foo(); }
dynamic_cast
- dynamic_cast可以把一个基类的指针转化成派生类的指针
- 其要求转化的类拥有多态性,即要有虚函数
- 对于类型上溯
upcast而言,即把派生类转化成基类,其实是一个从有到无的过程,因为派生类拥有基类的所有成员变量和成员函数 - 而对于类型下溯
downcast而言,由于派生类可能包含基类所没有的成员变量和成员数据,其实现的原理是在虚函数表中维护了type_info,
虚继承
- 虚继承的实现是基于
vbptr,即指向虚基类的指针,使得所有派生类对象共享访问同一个虚基类,而不是创建独立的副本 - 虚继承解决了菱形继承带来的基类数据存在二义性副本的问题
- 对于虚继承而言,如果当前类没有创建自己的虚函数,则不会创建
vfptr即虚表指针,因为虚基类中已经有对应的虚表指针
对齐
- 为了优化CPU读取数据的效率,有了对齐这一机制
- 其原理是让数据的存储地址为其字节大小的倍数,从而在访问时更快
- 对齐的根本原因是CPU在取数据时只能按照对齐的方式来进行,比如4字节的数据存储在
0x0000001,那么就需要进行两次访存,分别取0x0000000~0x000001E和0x0000020~0x000003E,然后再将两个数据通过位运算拼接起来得到实际的数值,其时间开销是很大的 其决定因素是数据中的高字节类型,比如结构体中的最高字节数为8字节的double,则该结构体为8字节对齐,即每个数据类型都会被填充到8字节
- 通过
#pragma pack(n)可以限定对齐方式,比如#pragma pack(1)限定为1字节对齐,则不进行任何字节填充
union
- 联合是一种节省空间的类,其可以包含多个数据,但是在任意时刻只能有一个数据成员有值,某个数据成员被赋值后其他数据成员处于未定义状态
- union的内存空间由占最大字节的类型决定,比如union包含double,int,char,则其所占的内存空间由double决定,即8字节
- 其具有如下特点
- 默认访问控制符为 public
- 可以含有构造函数、析构函数
- 不能含有引用类型的成员
- 不能继承自其他类,不能作为基类
- 不能含有虚函数
- 匿名 union 在定义所在作用域可直接访问 union 成员
- 匿名 union 不能包含 protected 成员或 private 成员
- 全局匿名联合必须是静态(static)的
运算符重载
递增和递减
对于这类运算符
++,--,其同时存在前置和后置的版本1 2 3
int a = 1; a++; // 后置递增:先返回值,然后递增 ++a; // 前置递增:先递增,然后返回值
按理来说这两个运算符的参数和返回值类型都一样,为了区分,通过提供额外的
int类型参数,表示其为后置版本1 2 3 4 5 6 7 8 9
T operator--(int) // 后置版本 { } T operator--() // 前置版本 { }
左值、右值、左值引用、右值引用、std::move
基本概念
左值为声明的局部变量,右值为临时变量,如下表达式,
a为左值,而1为右值;object_a为左值,A()为右值1 2
int a = 1; A object_a = A();
左值引用为对左值的引用,通过
&修饰符定义;右值引用为对右值的引用,通过&&修饰符定义1 2 3
int a = 1; int &left_ref = a; // 左值引用 int &&right_ref = 2; // 右值引用
- 声明的左值引用变量和右值引用变量本身是左值,函数返回的右值引用为右值
对于函数的参数而言,
const T&即可接受传入参数为左值,也可以是右值;而T&&只能是右值std::move可以将左值转化为右值,即static_cast<T&&>
应用
通过
std::move可以很好地避免拷贝带来的开销,可以实现移动构造函数,考虑如下的情景,在实现类的拷贝构造函数时,可以通过const T&减少传入参数的拷贝操作,但是却避免不了深拷贝带来的额外的拷贝开销1 2 3 4 5 6 7 8 9 10 11 12 13
class Array { private: int* data; int length; public: Array(const Array &other) { length = other.length; data = new int[length]; for (int i = 0; i < length; i++) { data[i] = other.data[i]; } } };
假设我们对于传入的被拷贝的对象,我们后续不会再使用,那么可以使用如下的方式实现该拷贝构造函数,通过如下的方式,背拷贝对象
other的data依然会指向该数据的地址,我们理应执行other.data = nullptr;,但是由于参数的类型为const Array&,因此无法执行修改操作1 2 3 4
Array(const Array &other) { length = other.length; data = other.data; }
当然对于上述问题,我们可以将参数类型改为普通的左值引用
Array&,但是这样又会导致参数无法为右值,即无法使用这样的方式Array(Array())进行参数传递,可行的方法为将参数定义为右值引用Array&&,这样实参既可以是右值,也可以通过std::move将左值转化为右值传入,并且避免了拷贝带来的开销,将源数据设置成可安全析构的状态,是因为源数据对象有时会在移动后,被销毁,所以为了避免影响到当前的数据地址,所以将其设置成nullptr1 2 3 4 5
Array(Array &&other) { length = other.length; data = other.data; other.data = nullptr; }
移动构造函数应该是
noexcept,因为移动构造函数不分配任何资源,只是将其他对象的内存”转交”到自身,noexcept的位置处在参数列表和初始化列表的冒号之间,且在声明和定义中都需要指定noexcept在标准库中
std::move接受的参数是右值引用,为什么左值可以作为实参传入呢,这里要引入万能引用的概念,通过将该参数定义为模板的类型参数T,该参数就既可以接受左值引用,也能接受右值引用1 2 3 4
template<typename T> void foo(T&& param) { }
这是因为当传入的值为左值时,
T会被识别为T&,根据折叠规则,T& &&就是T&折叠规则:如果任一引用为左值引用,则结果为左值引用。否则,结果为右值引用,即当存在多重引用时,最终的引用类型是左值引用(
&)优先于右值引用(&&)组合类型 折叠后的类型 T& &T&T& &&T&T&& &T&T&& &&T&&std::forward利用引用折叠规则,如果传入的参数类型为左值引用,那么返回的就是左值引用,返回的参数为右值引用,则返回的参数为右值引用,因为对于传入的参数类型
T,其返回类型为T&&,如果T为左值引用,那么根据引用折叠规则,其返回的类型就是左值引用。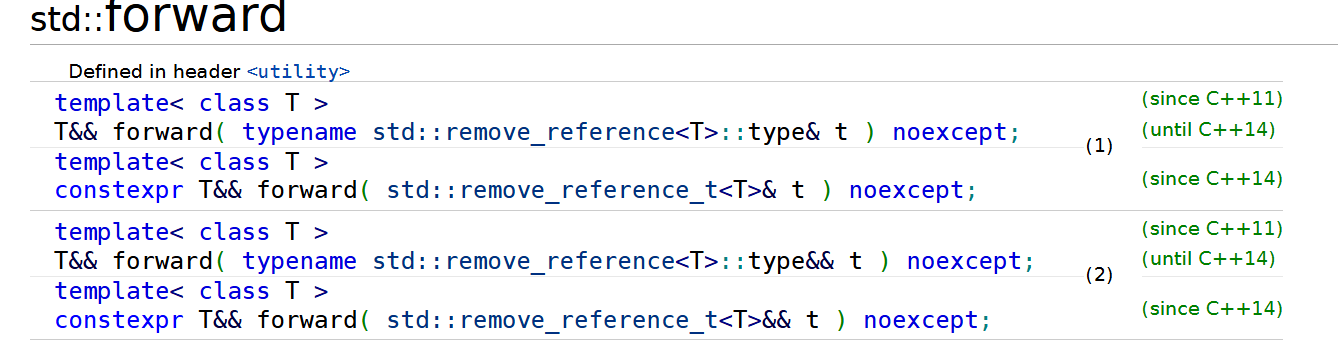
动态内存管理
使用
new和delete来申请和释放内存,如下是基本的使用方式1 2 3 4
int *p = new int(42); delete p; int *arr = new int[10]; delete[] arr;
placement new:在已分配的内存地址上构建对象,通过new (address) Type(args...);1 2 3 4 5 6 7 8 9 10 11 12 13
#include <memory> #include <iostream> int main() { int *a = new int[4]; new(a + 3) int(100); for (int i = 0; i < 4; i++) { std::cout << a[i] << std::endl; } delete[] a; return 0; }
智能指针
一般来说动态对象通过new来分配内存空间,并在合适的时机使用delete来释放内存,如果忘记释放,则会出现内存泄漏的问题。
为了防止出现上述情况,提出了智能指针来管理动态对象
shared_ptr
- 支持的方法
p.get():返回智能指针中保存的内置指针p.use_count():引用计数的值p.unique():如果p.use_count()为1,返回true,否则返回falsep.reset():若p是指向其对象的唯一shared_ptr,则reset会释放此对象p.reset():将p置空p.reset(q):将p指向q,q为内置指针p.reset(q,d):将p指向q,并指定使用函数d来释放内存
允许多个指针指向同一个对象,维护指向对象的计数器,当计数器为0时自动销毁该对象的内存空间
shared_ptr<T> ptr,其中T为指向对象的类型,通过make_shared<T>(args...)来创建1
shared_ptr<int> p = make_shared<int>(1); // 创建指向int类型的指针p,且对象的初始值为1
其构造函数为
explicit,抑制了隐式类型转换,所以不能将一个内置指针隐式转化为只能指针,必须使用直接初始化,不能使用拷贝初始化1 2
shared_ptr<int> p1 = new int(123); // 错误:使用了拷贝初始化 shared_ptr<int> p1(new int (123)); // 正确:使用直接初始化
对于
shared_ptr作为函数参数的函数,其实参也不能传入内置的指针类型,而是应该用shared_ptr类型考虑如下情景,用到了
shared_ptr的引用计数功能,当引用计数为0时,则会自动释放该动态分配的内存1 2 3 4 5 6 7 8 9 10 11 12
void process(shared_ptr<int> ptr) { // 访问ptr的内容 }// 函数调用结束后,ptr就会被销毁掉,因此引用计数减一 int main() { int *x(new int(1024)); process(shared_ptr<int>(x)); // 使用临时对象传参 // 该语句指向后临时对象被销毁,引用计数减一,函数调用结束后,引用计数减一,因此动态分配内存被销毁 int j = *x; // 未定义,x为悬空指针(dangling pointer),指向了被释放的内存地址 }
不要用内置指针同时初始化多个
shared_ptr对象,会出现指向未定义内存的情况,如下,创建了两个相互独立的shared_ptr对象,因此引用计数不会相互影响;类似的例子还有使用p.get()得到的内置指针去初始化另一个shared_ptr对象,也是不推荐的写法1 2 3 4 5 6 7 8 9 10 11 12 13
#include <iostream> #include <memory> int main() { int *p = new int(42); std::shared_ptr<int> sp(p); // sp的引用计数为1 // 定义局部作用域 { std::shared_ptr<int> sp2(p); // sp2的引用计数为1 } // sp2被释放,引用计数归零,sp2所指向的内存被释放 std::cout << sp.use_count() << std::endl; // sp的引用计数仍为1 std::cout << *sp << std::endl; // 访问被释放的内存地址 }
- 智能指针相较内置的指针,在程序出现异常时,同样能够保证内存能被正确释放
enable_shared_from_this: shared_from_this
- 循环引用问题:循环引用
尾置返回类型
c++11中引入的trailing return type,用于将返回类型后置
1 2 3 4 5 6 7
auto func(int a, float b) float { return a + b; } template<typename T> auto func(T a, T b) decltype(a + b) { return a + b; }
模板
基本概念
模板参数列表中包括类型参数和非类型参数,在定义时,模板参数列表不能为空
类型参数通过
typename和class关键字声明非类型参数必须是常量表达式,即能够在编译期计算出值
在定义模板时,不会生成代码,只有当实例化模板(即使用模板时),才会生成对应版本的代码,且模板的实例化发生在编译期
函数模板既可以显示指明参数,也可以让编译器推导类型;类模板只能显示指明模板参数
比如如下,通过传入const char*,编译器会给字符数组末尾自动添加
\0,因此其输出为41 2 3 4 5 6 7 8 9 10
#include <iostream> template<typename T, unsigned int SIZE> constexpr unsigned int GetLen(T (&array)[SIZE]) { return SIZE; } int main() { std::cout << GetLen("123"); return 0; }
类模板
类模板需要通过显示模板实参来创建实例化对象,编译器根据模板实参来实例化对应的类
默认情况下,类模板的成员函数只有当程序使用到时,才会进行实例化
当使用类模板类型时,必须提供模板实参,即
classname<T>,但是在类模板自己的作用域中可以直接使用classname,而不必提供模板实参对于模板类中的依赖类型,需要通过
typename来显式告诉编译器这是类型而非变量,所谓依赖类型就是依赖于模板参数的嵌套类型,格式如下1 2
typename 模板参数::嵌套类型名 typename 模板类<模板参数>::嵌套类型名
比如
1
typename vector<T>::size_type sz;
类型别名:通过使用模板类型参数来定义类型别名,见下述类型别名定义,
twin就成为了pair<T,T>的类型别名1
template<typename T> using twin = pair<T, T>
C++20
coroutine
协程为用户态的线程,比多线程更轻量化,可以理解为操作系统中的纤程(fiber)
成为coroutine的条件
包含以下任意语句的函数都能成为协程
co_await:挂起当前协程,等待某个操作执行结束后恢复当前协程的执行co_yield:中止当前协程,并返回值co_return:结束当前协程,并返回值
限制条件
- 不能用可变参数
- 不能直接使用
return语句 - 不能使用推导类型的返回值(auto)
consteval,constexpr,构造函数,析构函数,main函数不能成为coroutine
与coroutine相关联的元素
promise object:在协程内部操纵协程,协程向此对象提交结果和抛出异常coroutine handle:协程句柄,从外部操纵协程,用于恢复协程的执行以及摧毁协程coroutine state:协程的状态信息,包含- promise object
- 参数
- 用于表示当前挂起点的信息,从而使得在恢复执行时指导从何处开始继续执行
- 当前的作用域中包含的局部变量
coroutine开始执行的步骤
- 为
coroutine state分配内存空间 - 将所有的函数参数拷贝给
coroutine state - 调用
promise object的构造函数 - 调用
promise.get_return_object()来获取协程的返回值,协程的返回值会在协程被挂起(suspend)时返回给调用者 - 调用
promise.initial_suspend(),并通过co_await等待其执行,执行完毕后开始真正执行协程中的内容
co_await的对象
- 对于自定义的co_await的对象(一般被称为awaitable object或awaiter),其需要满足如下要求
- 包含
await_suspend、await_ready、await_resume函数
- 包含
await_ready返回布尔值,用于说明是否应该被阻滞,如果是false,则会进行阻滞,否则就不会进行阻滞<coroutine>中给出了两个默认的实现,即std::suspend_always和std::suspend_never这两个结构体,顾名思义,前者会阻滞协程,后者不会阻滞协程
协程返回对象
对于自定义返回对象,其必须包含一个名为
promise_type的嵌套类型,即对于自定义类型R,其包含R::promise_type且
promise_type需要有名为get_return_object()的函数,其返回R类型的实例使用例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
#include <concepts> #include <coroutine> #include <exception> #include <iostream> struct ReturnObject { struct promise_type { ReturnObject get_return_object() { return {}; } std::suspend_never initial_suspend() { return {}; } std::suspend_never final_suspend() noexcept { return {}; } void unhandled_exception() {} }; }; struct Awaiter { std::coroutine_handle<> *hp_; constexpr bool await_ready() const noexcept { return false; } void await_suspend(std::coroutine_handle<> h) { // h.resume(); if (hp_) { std::cout << "suspend called" << std::endl; *hp_ = h; hp_ = nullptr; } else { std::cout << "handle is null" << std::endl; } } constexpr void await_resume() const noexcept {} }; ReturnObject counter(std::coroutine_handle<> *continuation_out) { Awaiter a{continuation_out}; for (unsigned i = 0;; ++i) { co_await a; // 这里counter协程被挂起,等待Awaiter a std::cout << "counter: " << i << std::endl; } } int main() { std::coroutine_handle<> h; counter(&h); for (int i = 0; i < 3; ++i) { std::cout << "In main1 function\n"; h(); h(); } h.destroy(); }
数据结构
哈希表(散列表)
为了处理哈希冲突,主要有如下两种方法
- 开放地址法
- 线性探测:通过一次哈希得到的哈希值,若该位置已经存储了信息,则线性查找下一个位置,直到找到为止,此方法会产生原始聚集问题
- 二次探测:在线性探测的基础上采取倍增思想,每次步长呈平方增长,此方法会产生二次聚集问题
- 双哈希:对于探测步长,使用另一个哈希函数来进行计算得出,保证经过第一次哈希到同一位置的不同元素的探测步长不一样,第二个哈希函数需要满足如下要求
- 和第一个哈希函数不一样
- 不能输出为0,一般形式为$stepSize = constant - ( key \% constant )$,其中constant为小于数组长度的质数
- 链表法:对于每个哈希值拉一个链表存储所有的值
设计模式
对象池
- 对于频繁销毁创建的对象,不断使用
new/delete创建和销毁,会产生较大的开销,因此,对象池被提出来解决这种场景,将不需要使用的对象设置为不激活状态,并放在对象池中,当需要新的对象时,就从对象池中取出对象,并将其激活 - 当对象池中的对象数量无法满足需求时,再创建新的对象
单例模式
- 只存在一个实例化的对象,并提供一个全局的访问点
其在实现上分为懒汉模式(lazy singleton)和饿汉模式(eager singleton)
懒汉版在单例实例第一次使用时才初始化,在c++11后,采用静态局部变量local static可以满足线程安全,其被称为Meyer’s Singleton
1 2 3 4 5
static Singleton& getInstance() { static Singleton instance; return instance }
饿汉版在程序运行时就将单例实例初始化,一般采用non-local static的方式实现
1 2 3 4 5 6 7 8 9 10 11
class Singleton { private: static Singleton instance; public: Singleton& getInstance() { return instance; } } Singleton Singleton::instance; // 初始化静态成员,即单例实例对象
工厂
简单工厂
- 工厂类提供接口根据传入参数创建不同的派生类对象
- 添加新的对象时需要修改工厂类,这违背了开闭原则
工厂方法
- 创建工厂基类,派生出生成不同对象的工厂
- 当需要添加新的对象时,只需要派生出新的工厂即可
抽象工厂
- 和工厂方法类似,区别在于抽象类工厂可以多种商品(如鞋类和衣服类),比如工厂方法规定只能生产一种商品(如鞋类)
- 工厂方法和抽象工厂虽然都没有违背开闭法则,但是每次增加新的对象时都需要新派生出一个工厂类,还是比较麻烦,更优雅的实现见深入浅出工厂模式
操作系统
死锁
两个进程都在等待对方释放锁,导致陷入僵持,无法继续
- 死锁条件
- 互斥条件(一个资源只能被一个进程占用)
- 请求并保持条件(请求资源而阻塞时,对以获得的资源不进行释放)
- 不剥夺条件(在进程没有使用完资源之前,不能剥夺,只能自己释放)
- 循环等待(循环等待资源,类似循环引用导致无法使引用计数为零导致内存泄漏的问题)
- 防止死锁的方法
- 死锁预防:打破死锁条件
- 死锁避免:使用算法来分配资源防止进入死锁状态,比如银行家算法
- 银行家算法本质上就是在检查是否存在合法地进程执行序列(安全序列),具体算法可参考操作系统——银行家算法
- 死锁检测和解除:抢占资源或者终止进程
计算机组成原理
缓存
由于cpu的处理速度和访问内存的速度不匹配,因此通过缓冲来缓解这种不匹配,来减少访存的次数
多级缓存:L1,L2,L3缓存,数字越大离cpu越远,离内存越近
如何提高缓存的hit rate,利用局部性原理,每个CPU核有独立的L1缓存,L1缓存分为数据缓存和指令缓存
针对数据缓存,利用空间局部性原理,尽可能连续地访问内存空间,比如对于二维数组,按行优先的方式进行访问就可以满足空间局部性原理,因为二维数组本质上也是连续的内存空间,且按照行优先的方式进行存储(即按行存储),如下
1 2 3 4 5 6 7
for (int i = 0; i < n; i++) { for (int j = 0; j < m; j++) { cout << a[i][j] << endl; } }
再比如对于初始随机打乱的一维数组,要将数组中小于8的元素置为0,实现的方案有如下两种可选方案,对于乱序的数组,其操作具有随机性,因此无法很好地利用指令缓存来进行相同的指令操作,而有序的数组,可以很好地利用指令缓存,这是由于CPU具有分支预测器,可以根据历史的命中数据来对未来进行预测,提前将该分支的指令仿真指令缓存中去,对于有序的数组就可以大大提高分支预测器的准确性,从而使得缓存的命中率提高
先对数组进行排序,然后遍历有序的数组,通过if语句进行判断,将小于8的元素置为0
先遍历数组,进行置0的操作,然后排序
FAQ
静态成员变量的初始化问题
- 静态成员变量需要在类外进行初始化,否则会出现
undefined reference报错,因为在类内声明时并不会给该静态成员变量分配存储空间,只有当在类外初始化后才会分配 - 对于constexpr类型的静态数据成员,其可以在类内初始化,其应用场景比如通过static constexpr int类型来指定普通数组成员的维度。
为什么普通的数据成员定义为const类型,无法指定数组成员的维度,因为类的编译过程是先编译声明语句,在声明语句中数组成员的维度作为数据成员还没有进行初始化,只有当对象被实例化时,其才被赋予类内初始值
声明和定义
- 注意这两个术语,比较容易混淆,声明很好理解,定义就是我所理解的实现,包括函数的定义、静态成员变量的定义等